Explanation
Architecture
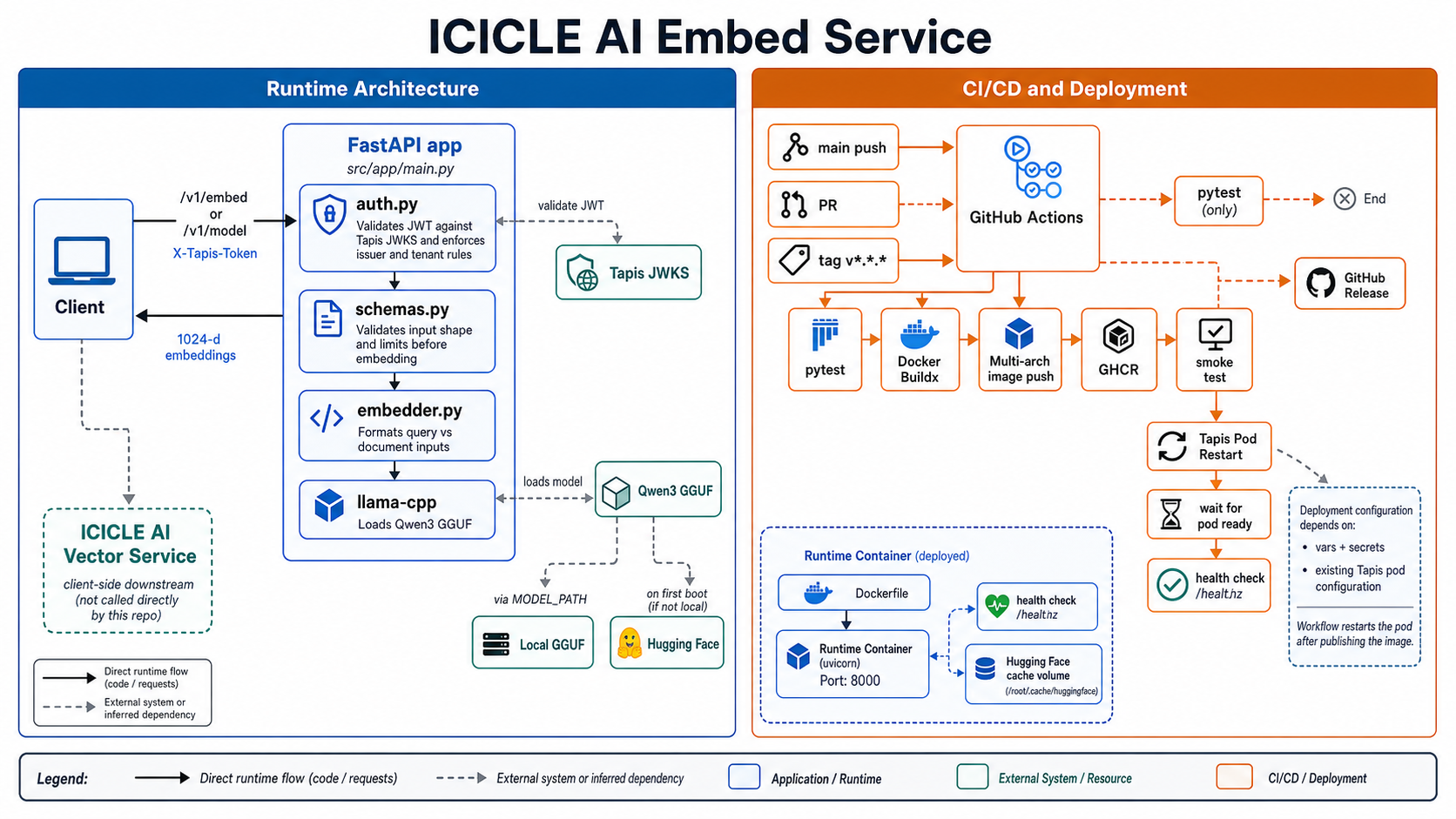
The diagram above shows how the service sits between client requests and the underlying model on Tapis Pods, with persistent volume storage for cached GGUF weights and the workflow-driven path from GitHub to GHCR to the running pod.
For a closer look at what happens inside a single request — auth, validation, the serialized embedder, and pooling — the textual flow below maps to the actual code path in src/app/:
ICICLE AI Embed Service
┌──────────────────────────────────────────────────┐
│ │
Client Request │ FastAPI Application │
(X-Tapis-Token) │ │
| │ ┌──────────┐ ┌───────────────────────────┐ │
v │ │ Auth │ │ /v1/embed handler │ │
┌──────────┐ │ │ (JWKS) │ │ │ │
│ POST │────────>│ │ │───>│ Pydantic validation: │ │
│ /v1/embed│ │ │ Verify │ │ - non-empty strings │ │
│ │ │ │ JWT sig │ │ - len <= max_chars │ │
└──────────┘ │ │ Check │ │ - count <= max_inputs │ │
│ │ expiry │ │ │ │
│ │ Validate │ │ Format query / document │ │
│ │ tenant + │ │ template │ │
│ │ access │ └───────────┬───────────────┘ │
│ └──────────┘ │ │
│ v │
│ ┌───────────────────────────┐ │
│ │ Embedder (singleton) │ │
│ │ │ │
│ │ ┌─────────────────────┐ │ │
│ │ │ threading.Lock │ │ │
│ │ │ (serializes │ │ │
│ │ │ embed() calls) │ │ │
│ │ └──────────┬──────────┘ │ │
│ │ v │ │
│ │ ┌─────────────────────┐ │ │
│ │ │ llama_cpp.Llama │ │ │
│ │ │ embedding=True │──┼───┼──> Metal / AVX2 / NEON
│ │ │ pooling: last │ │ │ (quantized matmul)
│ │ │ GGUF on disk │ │ │
│ │ └─────────────────────┘ │ │
│ └───────────────────────────┘ │
│ │ │
│ v │
│ L2 normalize (opt) │
│ │ │
│ v │
│ JSON response │
└──────────────────────────────────────────────────┘
How Embedding Works
raw text ──> optional query template ──> tokenize ──> forward pass ──> pool ──> normalize
"how do "Instruct: ...\n [bos, ..., transformer last v / |v|
plants Query: how do eos] (quantized) token
make food" plants make food" hidden
state
- Tokenization: handled by llama.cpp from the GGUF's bundled tokenizer.
- Forward pass: 28 transformer layers, 1024-dim hidden, run on Metal on macOS / AVX2-AVX-512 on x86 / NEON on ARM. Quantized weights mean every matmul is int8 (Q8_0) or 4-bit (Q4_K_M variants).
- Pooling: last-token pooling, baked into the GGUF metadata. The service does not override this.
- Normalize: L2 normalize on by default so dot product == cosine similarity downstream.
Design Decisions
- llama.cpp over PyTorch/transformers: no PyTorch install (saves ~2 GB), native Metal on Mac, hand-tuned AVX2/AVX-512/NEON kernels for CPU quantized matmul. Materially faster than PyTorch on CPU for this model size, with a fraction of the memory footprint.
- Q8_0 by default: for embedding models the quality delta vs fp16 is within retrieval noise. Drop to f16 only when you need reference vectors.
- Single-process, serialized embedding:
llama-cpp-python'sembed()mutates the shared context and is not thread-safe. The embedder holds athreading.Lockand runs work onanyio.to_threadso the FastAPI event loop stays free. For higher throughput, scale horizontally (more replicas) rather than threading a single model. - Pooling type comes from the GGUF: Qwen3-Embedding uses last-token pooling, baked into the file's metadata. Overriding
pooling_typewould silently corrupt the vectors. - Instruction-aware by default: Qwen3-Embedding expects query/document asymmetry. The
input_typeflag keeps clients from having to format the template themselves;instructionlets advanced users override it per-request. - L2-normalize by default: the vector service uses cosine similarity; normalized vectors make scores comparable across models and turn dot product into cosine.
- No server-side chunking: the service embeds what it's given. Callers own chunking, because chunk strategy is domain-specific.
- Auth boundary mirrors the vector service: same Tapis JWT validation (signature + issuer + access-token-type + tenant). One token works across the embed→store→retrieve pipeline.
Security Posture
- Mandatory Tapis JWT on every endpoint except
/healthz. There is no bypass flag — auth is on whether you're running locally or in production. JWTs are validated withRS256only (nonone-algorithm fallback), checked for expiration, issuer,tapis/token_type == "access", andtapis/tenant_id == "icicleai". - No request-body logging. Logs include payload shape (
len(texts),total_chars) and the authenticatedusername, never the raw input text. Tokens are never logged. - Request size limits.
MAX_INPUTS_PER_REQUESTandMAX_CHARS_PER_INPUTcap how much work a single request can ask for, validated by Pydantic before the embedder is touched. - Single shared model context. Requests are serialized at the embedder level so a malicious client cannot race the GGUF context into an inconsistent state.
- No outbound network at request time. The only network call is the one-time
huggingface_hubdownload at startup, skipped entirely whenMODEL_PATHis set. - Container hygiene. The Docker image runs as a non-root
appuser, ships only runtime libs (no compilers in the final layer), and writes the model cache into a mountable volume so weights persist across restarts without baking into the image. - Fail-closed startup. If model load fails, the process exits with a clear message rather than serving a half-initialized embedder.
Data handling notice: input text is held in memory only for the duration of the request. Nothing is persisted by this service.